진법과 자바의 변수, 메모리¶
2진법¶
덧셈¶
우리가 흔히 실생활에서 사용 중인 10진법과 마찬가지로 오른쪽(LSB__Least Significant Bits)에서 왼쪽(MSB__Most Significat Bits)으로 자릿수에 맞춰서 더해주면 된다.
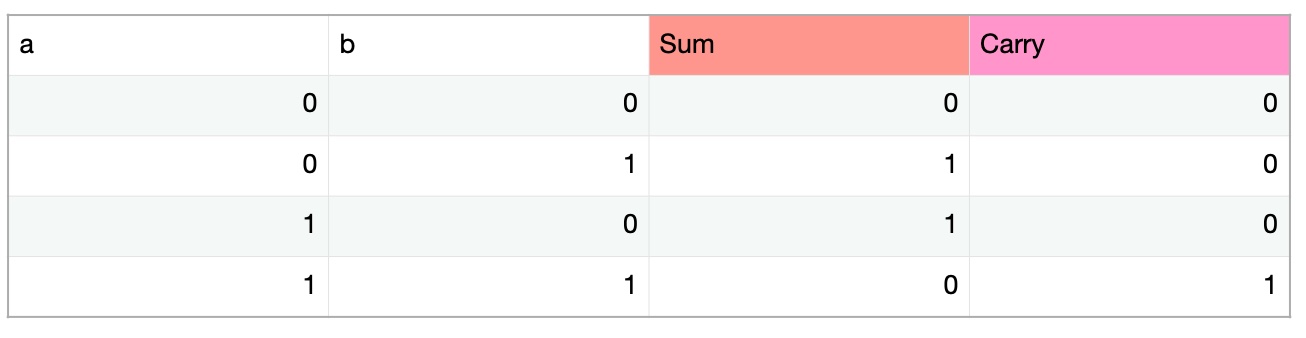
아래 이미지는 0 과 1 두 수로 만들 수 있는 합산 결괏값인 Sum과 그에 대한 버림인 Carry 를 표현한 것이다. 이때 나중에 살펴보겠지만 1 과 1 같이 더해서 Carry가 발생하는 경우를 자릿수가 넘쳐 버려졌기 때문에 오버플로우라 한다.
여기서 중요한 점은 Sum은 XOR 게이트, Carry는 AND 게이트 를 통해 구할 수 있다는 것이다. XOR 게이트란 true 의 개수가 홀수일 때 true , 그 외에는 false 를 반환하는 논리 연산을 의미하며 AND 게이트란 모두 true 일 때 true , 그 외에는 false 를 반환하는 논리 연산을 의미한다. 이처럼 컴퓨터는 덧셈을 수행할 때 XOR 칩과 AND 칩을 이용하여 Sum과 Carry를 구하게 된다.
보수¶
보수는 더했을 때 n 이 되는 수를 의미한다. 다시 말해 n 의 보수는 곧 더했을 때 n 이 되어야 하기 때문에 2 의 보수는 더해서 2 가 되어야 한다는 의미다. 예를 들어 2진수에서 2의 보수는 0 이 된다는 의미와 같다.
만약 0101 이라는 10진수로 5 의 값을 갖는 2진수가 있다고 하자. 0101 의 2의 보수는 더해서 0000 이 나와야 하는 수, 다시 말해 자리올림이 발생해서 크기로 인해 버려져야 하는 수이기 때문에 1010 이 곧 2의 보수가 된다. 이를 10진법으로 나타내면 0101 의 10진수가 5 이기 때문에 0101 의 2의 보수인 1010 의 10진수는 -5 여야 한다.
음수 표현¶
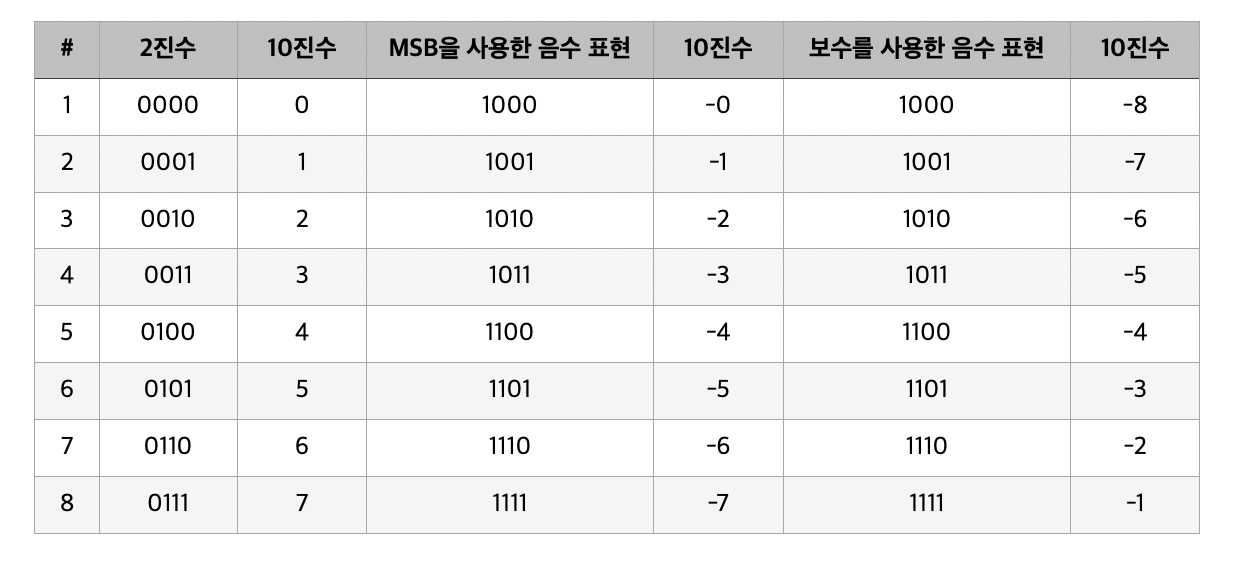
이렇게 보수를 통해서 2진법의 음수를 표현하는 방식을 유추할 수 있다. 우선 아래 이미지를 한 번 살펴보자.
아래 표와 같이 MSB(Most Significant Bits)인 가장 왼쪽의 비트를 0 일 경우 양수, 1 일 경우 음수로 표현 하여 나타낼 경우 두 가지 문제점이 발생한다. 하나는 0 이 두 번 중복된다는 점이고 그리고 보수를 제대로 표현할 수 없다는 점이다. 예를 들어 10진수로 2 를 나타내는 0010 값과 MSB를 사용한 음수 표현의 10진수 값이 -2 인 1010 을 더하게 되면 1100 으로 결괏값으로 -4 가 나온다.
이러한 문제점을 해결하기 위해 등장한 것이 2의 보수를 사용 하는 방법이다. 2의 보수는 1의 보수를 구한 다음 그 결괏값에 1 을 더하여 쉽게 구할 수 있다. 1의 보수는 더해서 1 이 되어야 하는 수를 의미하기 때문에 다시 말해 2진법에서의 1의 보수는 곧 0 을 1 로, 1 을 0 으로 바꾸는 걸 의미한다. 따라서 0 과 1 의 수를 서로 바꿔 준다음 1 을 더해주면 쉽게 2진수의 음수 표현을 구할 수 있다. 예를 들어 10진수 7 을 의미하는 2진수 0111 의 음수는 1의 보수를 통해 구한 결괏값인 1000 에 1 을 더한 1001 이 된다. 10진수끼리의 덧셈 또한 0 이 되며 진수끼리의 덧셈 또한 0111 과 1001 의 덧셈이기 때문에 버림으로 인해 0000 이 된다는 걸 알 수 있다.
8진법, 16진법¶
컴퓨터에서 2진법으로 값을 표현할 때 64비트 컴퓨터가 레지스터에 값을 표현하려면 자리수가 상당히 길어질 것이다. 따라서 이러한 문제를 보완하기 위해 8진법과 16진법을 사용한다. 8진법의 경우 $0$ 부터 $7$ 까지의 숫자만 있으면 되기 때문에 별다는 기호가 필요하지 않으나 16진법의 경우 $10$ 이부터는 두 자리수이기 때문에 별도의 표현 방식이 필요해서 이를 $A$ 로 표현하여 이후 차례대로 증가하여 최대값인 $15$ 는 $F$ 다.
진법 변환¶
2진수를 8진수로 변환¶
쉽게 2진수를 뒤에서부터 3자리씩 끊어서 그에 해당하는 8진수로 바꾸면 된다. $8$ 이라는 값이 $2^3$ 이기 때문에 3자리씩 끊는다.
2진수를 16진수로 변환¶
8진수와 유사하게 2진수를 뒤에서부터 4자리씩 끊어서 그에 해당하는 16진수로 바꾸면 된다. $16$ 이라는 값이 $2^4$ 이기 때문에 4자리씩 끊는다.
자바의 변수¶
변수 (Variable)¶
정의¶
변수란, 단 하나의 값을 저장할 수 있는 메모리 공간 을 의미한다. 따라서 하나의 변수에는 단 하나의 값을 저장할 수 있기 때문에 새로운 값을 저장하면 기존의 값은 사라진다.
선언과 초기화¶
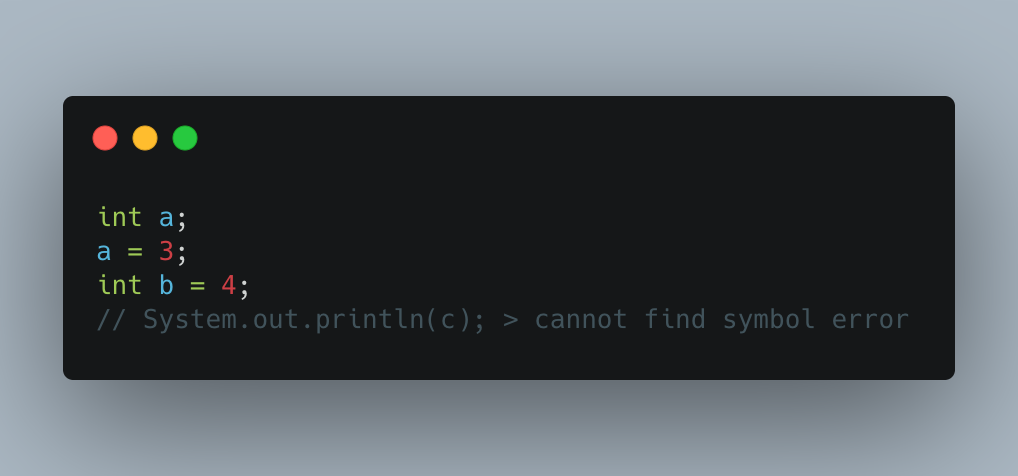
아래 이미지를 보면서 이야기하면 쉽다. int a; 와 같이 변수 a 에 어떤 자료형을 사용할 것인지 말해주는 것이 선언을 의미한다. 그리고 바로 아래 a = 3; 과 같이 실제 값(리터럴)을 할당( = ) 할 때 가장 처음 값을 할당해주는 걸 초기화라고 한다. 그리고 보통은 int b = 4; 와 같이 변수를 선언할 때 초기화를 함께 해준다.
여기서 유의할 점은 선언을 통해서 변수 테이블(Symbol Table)에 변수의 이름, 다시 말해 식별자(Identifier)를 지정하고 초기화를 통해 해당 식별자에 값의 주소를 연결 해주게 되는데 System.out.println(c) 와 같이 만약 선언하지 않아서 테이블에 존재하지 않는 값을 불러올 경우 해당 변수를 찾을 수 없다는 cannot find symbol error 가 발생한다.
명명규칙 및 컨벤션 (Convention)¶
프로그래밍에서 사용하는 모든 이름을 식별자(Identifier) 라고 한다. 이때 식별자는 같은 영역 내에서 서로 구분될 수 있어야 하기 때문에 아래와 같은 규칙을 지켜야 한다.
- 대소문자가 구분되며 길이에 제한이 없다.
- 예약어(keyword 또는 reserved word)를 사용해서는 안 된다.
- 숫자로 시작해서는 안 된다.
- 특수 문자는
_와$만 가능하다.
또한 권장하는 규칙, 다시 말해 네이밍 컨벤션 또한 아래와 같이 존재한다.
- 클래스 이름의 첫 글자는 항상 대문자로 한다. 이때 변수와 메서드 이름의 첫 글자는 항상 소문자로 한다.
- 여러 단어로 이루어진 이름은 단어의 첫 글자를 대문자로 한다. ( 카멜 케이스 )
- 상수의 이름은 모두 대문자로 하며 여러 단어로 이루어진 경우
_를 사용해 구분한다.
변수(variable)와 식별자(identifier)를 혼용 하는 경우가 많다. 변수는 그 정의에서도 알 수 있듯이 하나의 값, 다시 말해 데이터를 저장하고 또 새로운 값이 저장되면서 변할 수 있는 것 을 의미한다. 반면 식별자는 이러한 데이터를 단어 그대로 식별하는 데 사용하는 이름, 다시 말해 변수명 을 의미한다.
기타¶
변수의 스코프(Scope)와 라이프타임(Lifetime) 도 매우 중요한 개념이지만 이에 대해서는 아직 객체에 관해 배우지 않았기 때문에 객체와 메서드 개념을 배우는 객체 지향 프로그래밍 챕터에서 다뤄보고자 한다.
변수의 타입¶
값의 종류¶
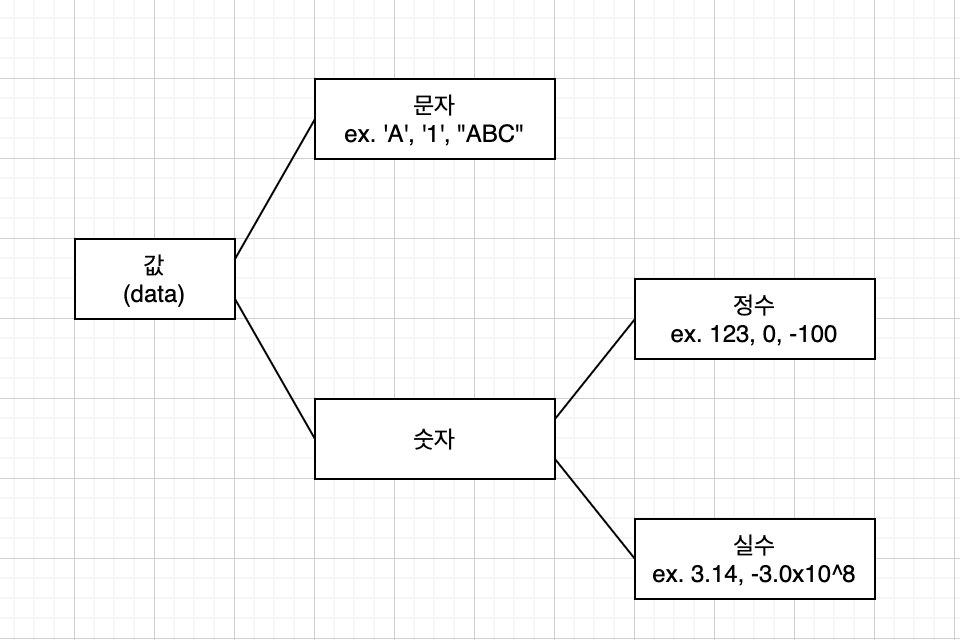
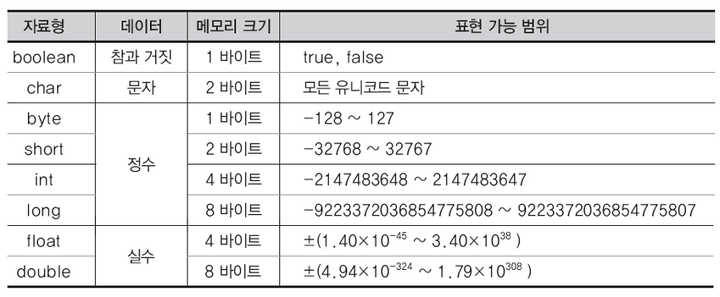
값의 종류는 크게 문자와 숫자로 나눌 수 있다. 그리고 다시 숫자는 정수와 실수로 구분이 되는데 이를 간단하게 나타내면 아래 이미지와 같다. 이때 자바의 자료형에서는 문자 자료형인 char , 숫자 자료형 중 정수 자료형인 byte , short , int , long 그리고 실수 자료형인 float , double 이 존재한다.
기본형 (Primitive Type)¶
기본형 변수는 실제 값(data)을 저장한다. 이때 유의할 점은 자바의 참조형 변수는 상호 간의 연산이 안 되기 때문에 실제 연산에 사용되는 것은 모두 기본형 변수이다.
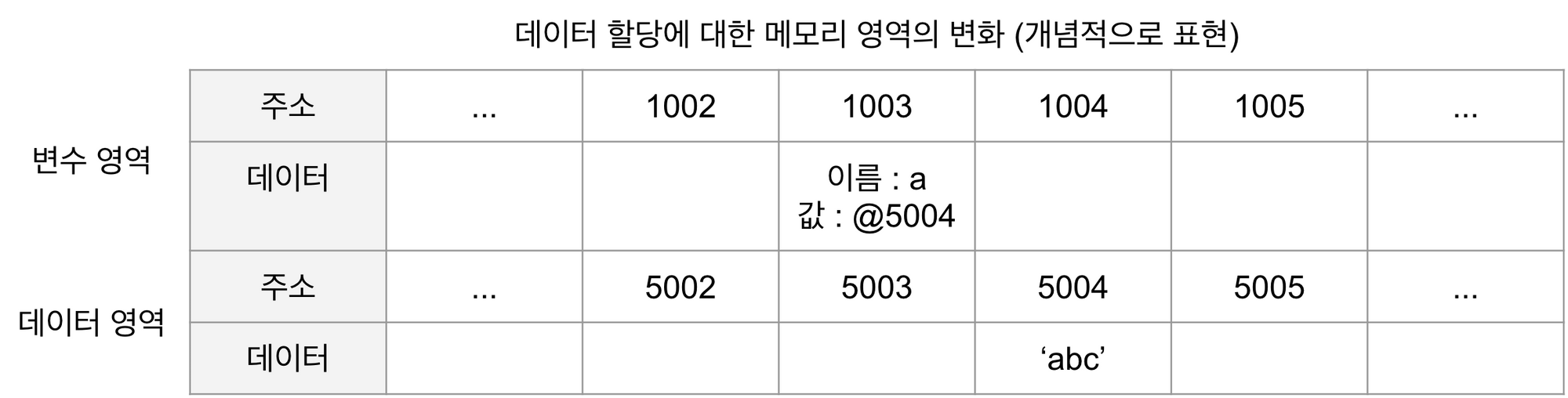
기본형의 경우 아래 이미지와 같이 불변하는 값, 다시 말해 데이터 영역에 저장되어 있는 상수(리터럴)의 주소를 변수가 가리키게 된다. 변수 a 가 abc 라는 상수 값의 주소인 5004 를 값으로 가리키게 되는 것이다. 그렇기 때문에 실제로 값을 가리키게-저장하게 되기 때문에 다른 변수 b 에 a 를 할당할 경우 똑같이 5004 번의 주소가 복제 된다.
논리형 ( boolean )¶
논리형은 기본적으로 참( true )과 거짓( false )만 다루면 되기 때문에 1 비트의 크기면 충분하지만 자바에서 데이터를 다루는 최소단위가 바이트이기 때문에 크기가 1 바이트로 지정됐다. 이때 기본값은 false 다. 주의할 점은 자바에서는 대소문자를 구별하기 때문에 True , TRUE , true 모두 다른 값을 의미한다는 점이다.
문자형 ( char )¶
문자형의 크기는 2 바이트다. 따옴표( '' )를 사용하여 단 하나의 문자만을 저장한다. 이때 실제로 변수에 저장되는 값은 문자가 아닌 문자의 유니코드(정수)가 저장된다.
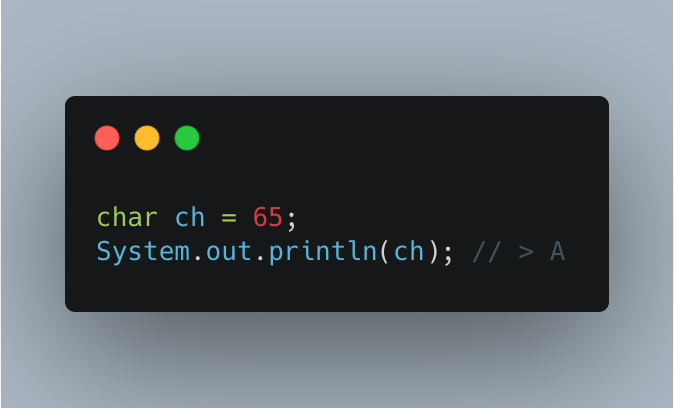
아래 코드 예시를 한 번 살펴보자. char 자료형을 사용하여 65 를 저장했음에도 불구하고 println() 이 ch 변수의 자료형이 문자형이기 때문에 자동으로 유니코드에 의해 A 라는 결괏값을 출력해줬다.
잠깐! 유니코드(Unicode) 란 무엇일까?
컴퓨터는 결국 이진법으로만, 다시 말해 숫자로만 모든 것을 이해하기 때문에 문자 자체도 숫자로 표현해줘야 한다. 이때 각 문자에 알맞은 숫자를 정해서 어떤 문자를 사용하면 이를 자동으로 정해진 숫자로 변환하며 컴퓨터가 이해할 수 있게 해주는 표가 바로 유니코드다.
정수형 ( byte , short , int , long )¶
byte: 1 바이트의 크기를 가진다.short: 2 바이트의 크기를 가진다.int: 4 바이트의 크기를 가진다. 기본 자료형(default data type) 이다.long: 8 바이트의 크기를 가진다.
모든 정수형은 부호가 있기 때문에 가장 왼쪽의 첫 번째 비트를 부호 비트(sign bit)로 사용 하고 나머지는 값을 표현하는 데 사용한다. 따라서 N 비트로 표현할 수 있는 부호있는 정수의 범위는 곧 $-2^{N-1}$ ~ $2^{N-1} - 1$ 까지다. 따라서 1 바이트의 경우 8 비트와 같기 때문에 byte 자료형에 저장할 수 있는 수의 범위는 곧 $-128$ ~ $127$ 까지다.
이때 유의할 점은 JVM의 피연산자 스택(operand stack)이 피연산자를 4 바이트 단위로 저장 한다는 점이다. 따라서 byte , short 자료형의 경우 필수적으로 저장공간을 절약해야 할 때 그 크기에 맞춰 사용하고 일반적인 경우에는 4 바이트보다 작은 자료형의 값을 계산할 때 이를 4 바이트로 변환해서 연산이 수행되기 때문에 오히려 int 자료형을 사용하는 게 훨씬 효율적이다. 더욱이 byte 자료형의 경우 앞선 예시에서 알 수 있듯이 범위가 매우 작기 때문에 연산의 결괏값이 예상하지 못한, 오버플로우가 발생 할 수 있다.
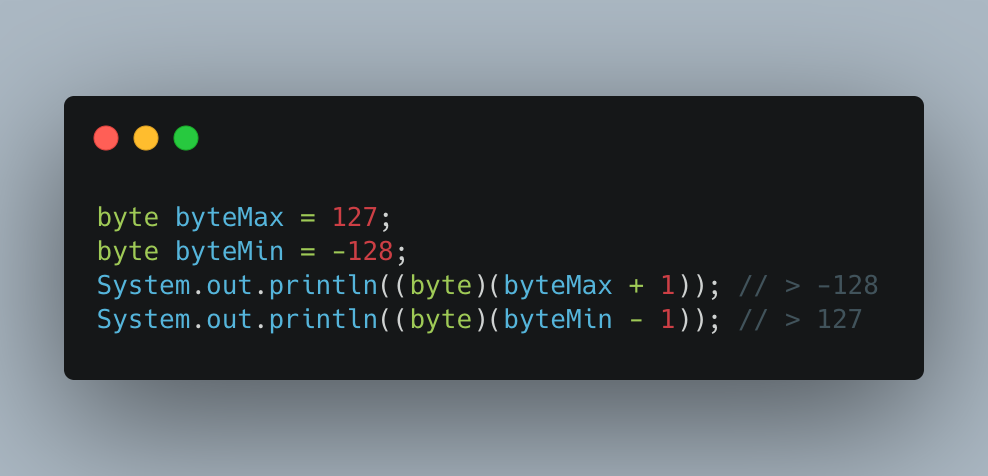
아래 이미지를 통해 오버플로우에 대해 간단하게 이해할 수 있다. byte 자료형의 최대값은 127 이고 최소값은 -128 이다. 그런데 각각 1 을 더하고 빼서 범위를 넘길 경우 아래와 같이 128 이 아닌 최소값 -128 로, -129 가 아닌 최대값 127 로 변한 것을 확인할 수 있다. 이처럼 변수가 표현할 수 있는 범위를 넘어선 것 을 오버플로우라고 한다. 이때 (byte) 라는 표현 방식은 형변환을 의미한다. 이에 관해서는 이따가 형변환 부분에서 더 자세히 살펴보고자 한다.
실수형 ( float , double )¶
float: 4 바이트의 크기를 가진다.double: 8 바이트의 크기를 가진다. 기본 자료형(default data type) 이다.
정수형의 int 자료형과 실수형의 float 자료형은 같은 4 바이트의 크기를 갖지만 실수형인 float 자료형이 정수형인 int 자료형보다 훨씬 더 넓은 범위의 숫자를 표현할 수 있다. 이는 어떻게 가능한 것일까? 바로 실수형은 부동 소수점(floating point) 방식으로 값을 저장하기 때문이다.
부동 소수점이란 값을 부호(Sign) , 지수(Exponent) , 가수(Mantissa) , 이렇게 세 부분으로 나누어 표현하는 방식을 의미한다.
- 부호: 부호 비트를 의미하며 1 비트의 크기를 가진다. 값이
0이면 양수를,1이면 음수를 의미한다. 정수형의 경우 부호를 바꾸기 위해서는 2의 보수법을 사용해야 하는데 실수형에서는 그렇지 않기 때문에 단순히 해당 부호의 값을0에서1로 또는1에서0으로 변경해주기만 하면 된다. - 지수:
float자료형의 경우 8 비트의 크기를 가진다. 부호있는 정수로float의 경우 $-127$ 부터 $128$ 까지 총 $2^8$ 개 만큼의 값을 저장할 수 있게 된다. - 가수: 실제 값을 저장하는 부분으로
float자료형의 경우 총 32 비트 중 부호와 지수를 뺀 나머지 23 비트의 크기를 가진다. 따라서float자료형은 2진수 23자리를 저장할 수 있게 되는데 이는 곧 10진수로 표현했을 때 7자리 정도의 숫자이기 때문에float자료형의 정밀도는 7자리가 된다.
예를 들어 $0.2 * 2^-1$ 과 같은 방식으로 부동 소수점을 표현할 수 있는데 이때 $0.2$ 가 곧 가수이고 컴퓨터는 이진법으로 이루어져있기 때문에 밑수가 $2$ 이면서 지수가 $-1$ 이 된다. 이를 정규화하게 되면 결국 첫 번째 자리의 숫자는 항상 $1$ 이 되고 결국 이러한 특징으로 인해 컴퓨터의 부동 소수점 표현은 주로 $1.m * 2^n$ 과 같다.
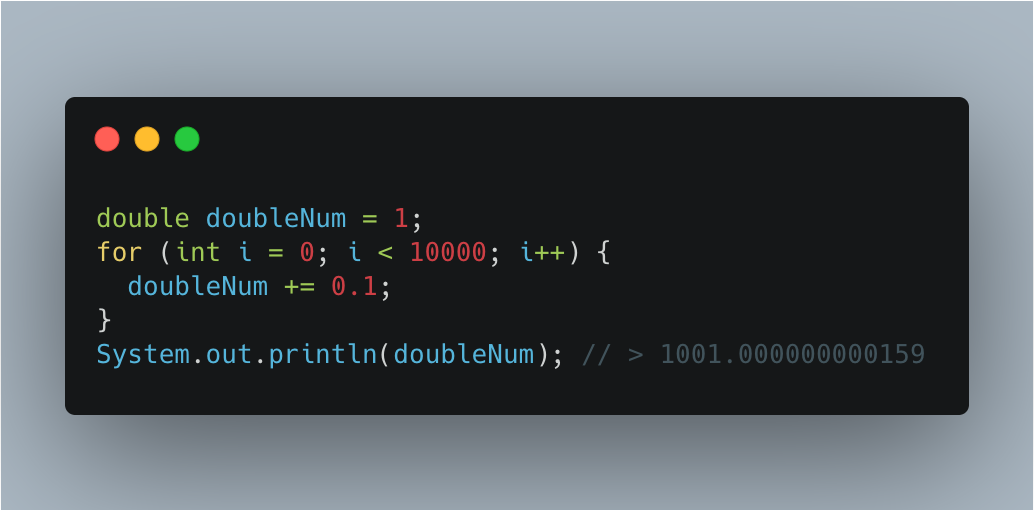
유의할 점은 이러한 지수 표현 방식으로 인해 아무리 값을 작게 해도 $0$ 을 표현할 수 없는 등의 정밀도에 대한 오류가 발생 하게 된다. 아래 코드 예시를 살펴보자. 0.1 을 10000 번 더했기 때문에 1001 이 나와야 될 것으로 생각하지만 실제 결괏값은 이상한 더미 데이터가 붙게 된다.
잠깐! 정규화 란 무엇일까?
정규화는 밑수보다 작은 한 자리까지 가수로 표현되는 것 을 의미하는 데 앞서 살펴봤듯이 컴퓨터에서는 이진법을 사용하기 때문에 밑수가 $2$ 라서 결국 가수가 $2$ 보다 작은 한 자리, 다시 말해 $1$ 이 된다.
잠깐! 실수형에서는 오버플로우가 발생 하지 않을까?
실수형에서도 물론 오버플로우가 존재한다. 다만 이때는 정수형과 달리 변수의 값이 무한대(Infinity) 가 된다. 그리고 정수형에는 없는 언더플로우(underflow)가 존재하는데 실수형으로 표현할 수 없는 작은 값 을 의미하며 이때 변수의 값은 $0$ 이 된다.
결론¶
기본형의 크기와 표현할 수 있는 최소값부터 최대값까지를 간단하게 나타내면 아래 이미지와 같다.
참조형 (Reference Type)¶
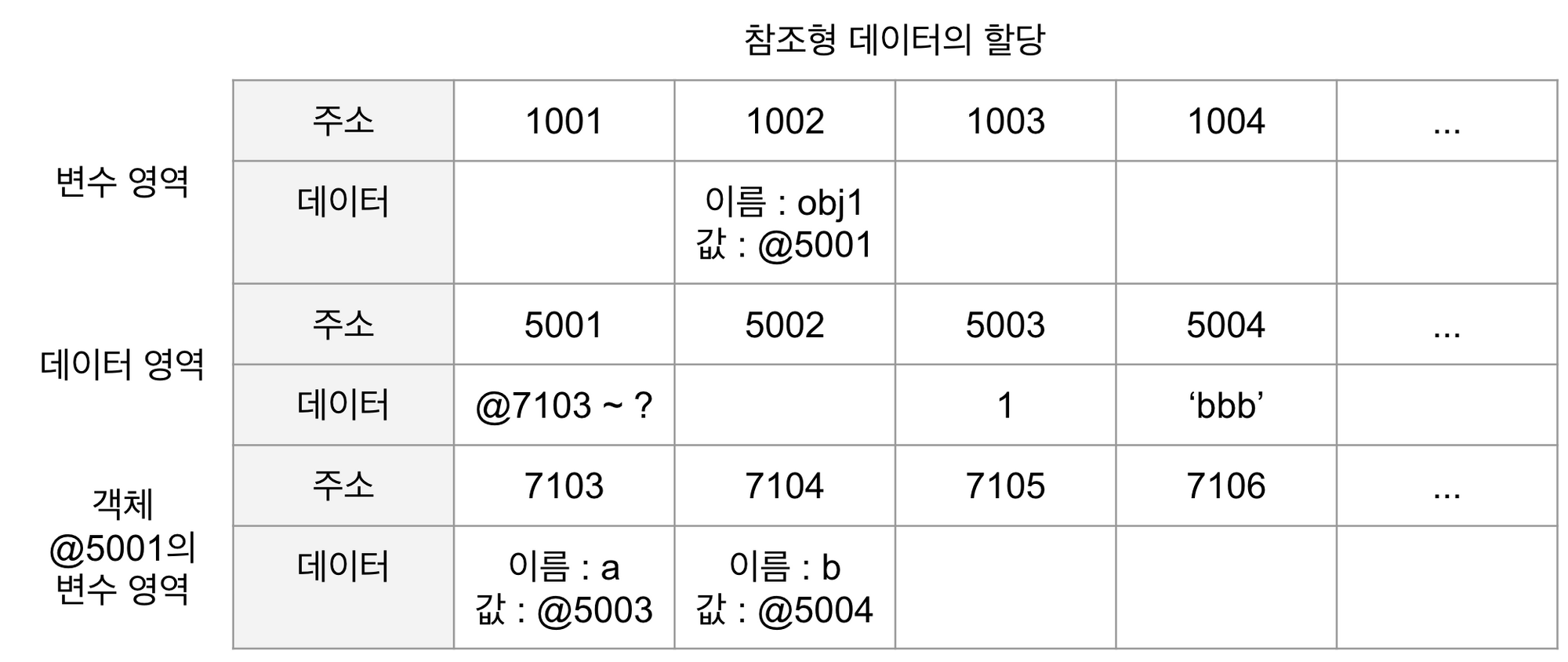
참조형 변수는 어떤 값이 저장되어 있는 주소(memory address)를 값으로 갖는다. 이는 다시 말하면 객체의 주소를 저장한다는 의미로 기본형을 제외한 나머지 다른 모든 타입이 참조형에 해당한다. 참조형 변수를 선언할 때는 변수의 타입으로 클래스의 이름을 사용하므로 클래스 이름이 곧 타입이 된다. 이때 new 라는 연산자와 함께 생성자(Constructor)를 사용한다. 그리고 그 결괏값으로 생성된 객체의 주소가 참조변수에 저장 되는 것이다.
아래 이미지를 통해 간단하게 살펴보자. 참조형 변수 obj1 의 값이 객체 501 를 가리키고 있고 해당 객체의 값은 7103 과 7104 를 가리키고 있는 걸 알 수 있다. 그리고 실질적인 값은 결국 7103 의 주소에 저장되어 있는 변수 a 가 저장하고 있는 값인 5003 과 7104 의 주소에 저장되어 있는 변수 b 가 저장하고 있는 값인 5004 가 된다.
이처럼 결괏값으로 생성된 객체의 주소인 5001 의 실질적인 값인 7103 고 7104 가 참조변수 obj1 에 의해 참조되는 것이다.
결론적으로 기본형의 경우 할당과 연산 때 값을 복제 하고 참조형의 경우 할당과 연산 때 값을 참조 한다는 차이점이 존재하는데 이를 통해 참조형 중의 경우 깊은 복사(Deep Copy)와 얕은 복사(Shallow Copy) 개념이 연관된다. 이에 관해서는 배열 챕터와 객체 지향 프로그래밍 챕터에서 더 자세하게 다뤄보고자 한다.
메모리와 데이터¶
컴퓨터는 모든 데이터를 0 또는 1 의 이진법으로 기억한다. 이때 0 또는 1 로만 표현할 수 있는 하나의 메모리 조각을 비트(bit) 라고 하는데 메모리는 이러한 비트들의 집합 으로 구성되며 각 비트는 고유한 식별자(unique indentifier)를 통해 위치를 확인 할 수 있다.
이때 비트를 묶어서 표현할 경우 검색 시간을 줄일 수 있는 것은 물론 표현할 수 있는 데이터의 개수도 늘어난다. 하지만 동시에 낭비되는 비트가 생기기 때문에 이러한 고민을 통해 등장한 것이 바이트(byte) 다. 1바이트는 8개의 비트로 구성돼 있다.
비트가 고유한 식별자를 가지고 있는 것처럼 바이트 또한 시작하는 비트의 식별자로 위치를 파악할 수 있다. 이처럼 바이트의 시작하는 비트가 곧 메모리 주소를 의미한다. 자바에서는 메모리에 1 바이트 단위로 일련번호가 붙어있는데 이 번호가 곧 메모리 주소 다. 이때 객체의 주소는 객체가 저장된 메모리 주소를 의미한다.
잠깐! 자료형(Data Type) 과 타입(Type) 의 차이가 뭔가요?
기본적으로 타입이 자료형을 포함하는 보다 넓은 의미다. 기본형의 경우 값(data)의 종류에 따라 구분이 되기 때문에 기본형의 종류를 이야기할 때는 자료형(data type) 이라는 용어를 사용하지만 참조형의 경우 객체의 주소를 저장하기 때문에 값이 아닌 종류(type)로 구별해서 타입(type) 이라는 용어를 쓴다.
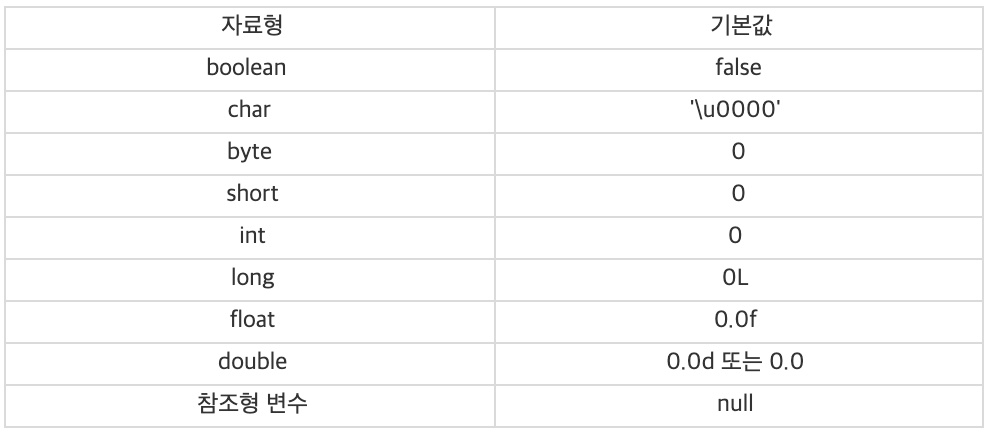
기본값¶
자바의 경우 자료형에 따른 변수의 기본값 은 아래 이미지 처럼 존재한다. 우선 이에 대해서 알기 위해서는 C언어에서의 쓰레기 값(Garbage Value) 에 대해서 알고 있으면 좋다.
쓰레기 값 (Garbage Value)¶
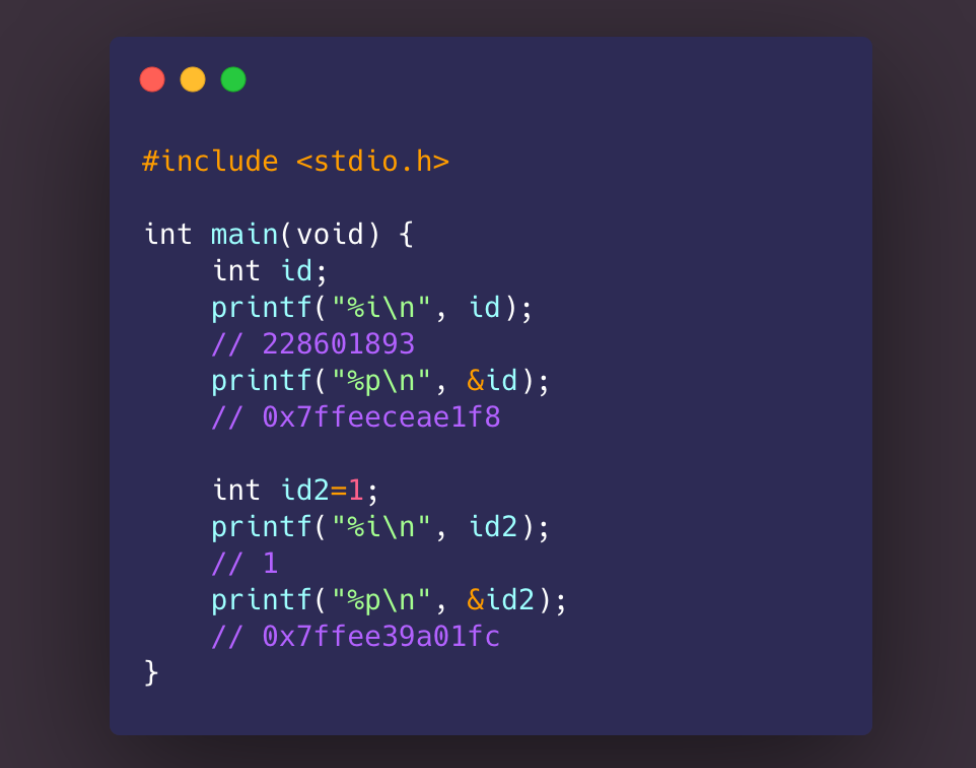
쓰레기 값이란 메모리에 어떤 변수를 선언하여 어떤 위치에 할당 시키고 그 변수에 어떤 값(데이터)을 할당 할 때 만약 값을 할당하지 않으면 무의미한 아무 값으로 초기화 되는 걸 의미 한다. C언어 코드를 통해 이를 살펴보면 아래 이미지와 같다.
선언만 int 자료형 id 에 값이 초기화 해주지 않았는데 임의의 값 228601893 이 할당 됐다. 반대로 변수 id2 의 경우 1 을 초기화해주자 알맞은 값인 1 이 결괏값으로 출력된 것을 알 수 있다.
이처럼 C언어에서의 변수는 선언과 동시에 초기화를 해줘야 예상하지 못했던 결괏값을 사용하게 되는 오류를 방지할 수 있게 되는데 자바의 경우 지역 변수에서는 선언만 했을 경우, 다시 말해 초기화하지 않은-값을 할당하지 않은 변수의 경우 스코프 내에서 사용할 수 없게 컴파일러 오류를 반환 한다.
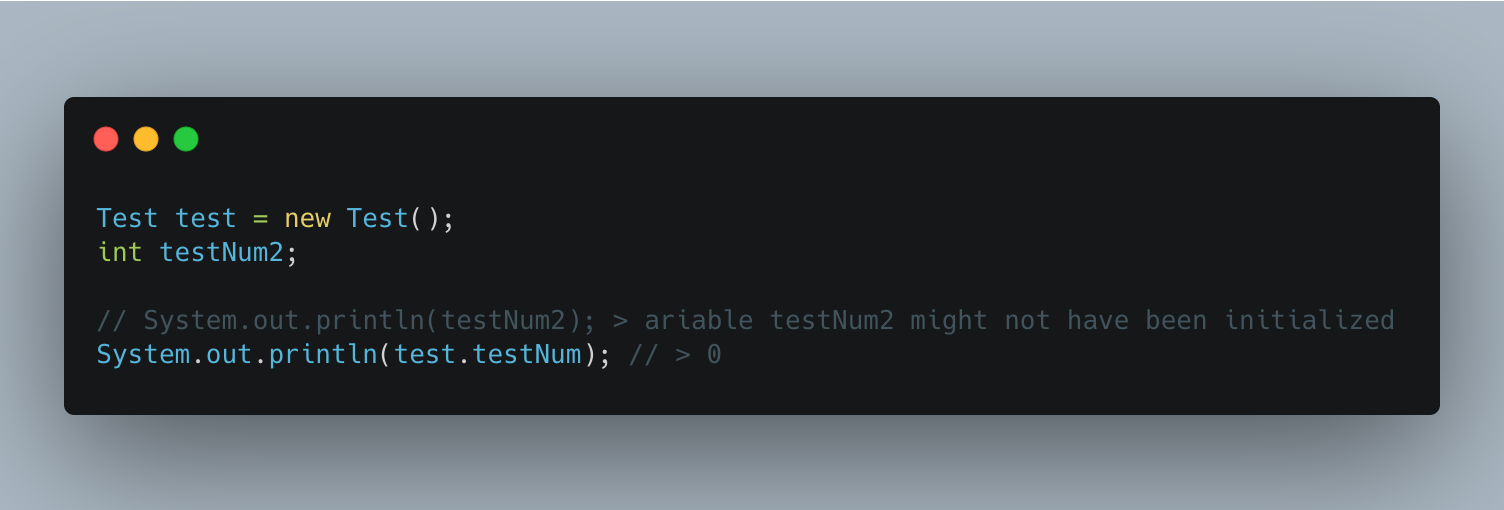
그렇다면 변수의 기본값이 왜 존재하는 걸까? 이는 멤버 변수와 같은 글로벌 변수를 위해 존재한다. 아래 이미지와 같이 Test 라는 객체에 testNum 이라는 int 자료형을 선언만 했을 경우 이를 사용하게 되면 0 이라는 결괏값을 출력하는 것을 확인할 수 있다. 반대로 지역 변수 tesNum2 은 선언만 했을 때는 따로 컴파일 오류를 발생시키지 않지만 이를 사용하려고 println() 을 통해 출력을 시도했을 때는 초기화되지 않았다는 컴파일 오류를 반환하는 것을 알 수 있다. 조금 더 자세한 내용은 변수의 스코프(Scope)와 생명주기(Lifetime), 그리고 객체 지향 프로그래밍 때 더 자세히 다뤄보고자 한다.
상수와 리터럴¶
상수 (Constant)¶
상수는 변수와 마찬가지로 값을 저장할 수 있는 공간이지만 변수와 달리 한 번 값을 저장하면 다른 값으로 변경할 수 없다. 변수와 선언하는 방법이 동일하지만 타입 앞에 키워드 final 을 붙여줘야 한다.
리터럴 (Literal)¶
우리가 흔히 사용하는 123 , "ABC" 와 같은 값들 또한 상수이다. 하지만 프로그래밍에서 상수와 이러한 값을 구별하기 위해 기존에 우리가 아는 상수를 리터럴이라는 용어로 부르기로 했다. 따라서 리터럴은 그 자체로 값을 의미하는 것이라 생각하면 된다. 변수, 상수, 리터럴을 구분하면 간단하게 아래 이미지와 같다.
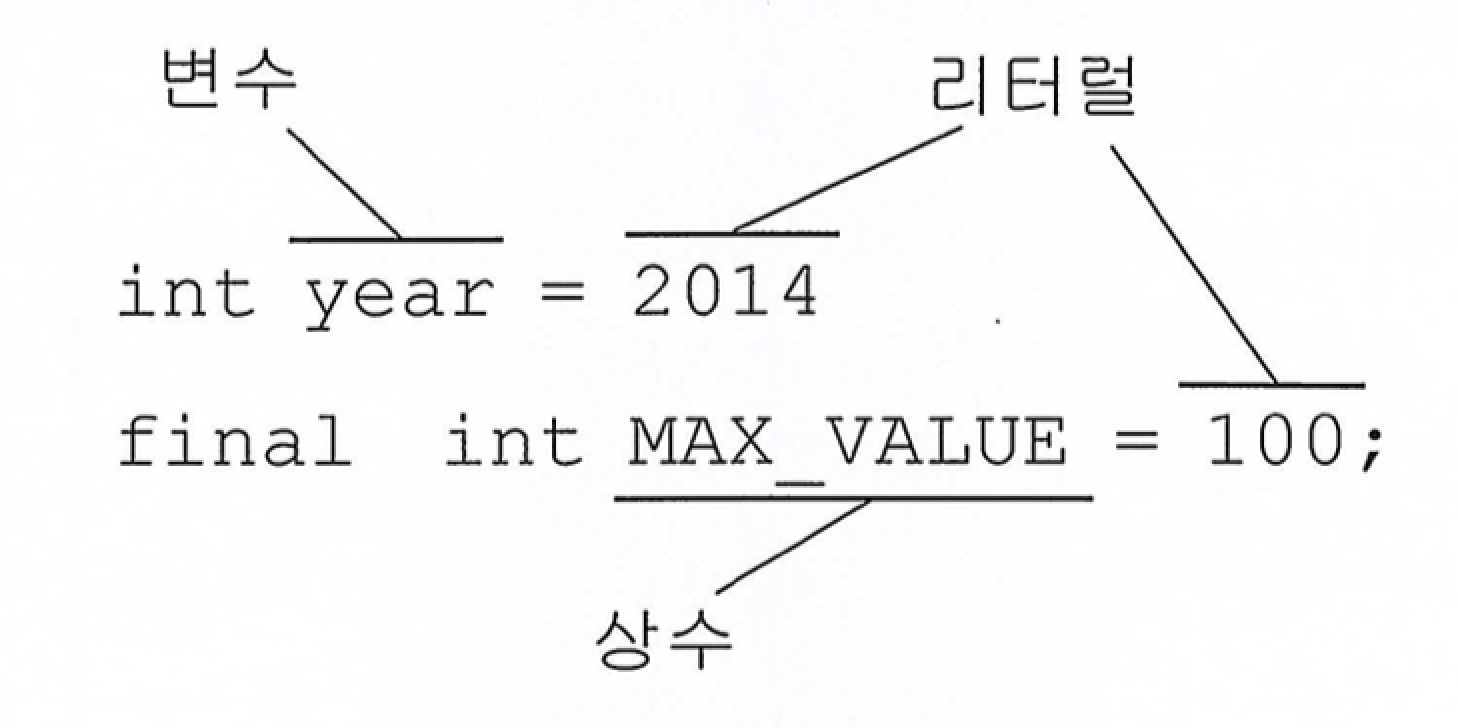
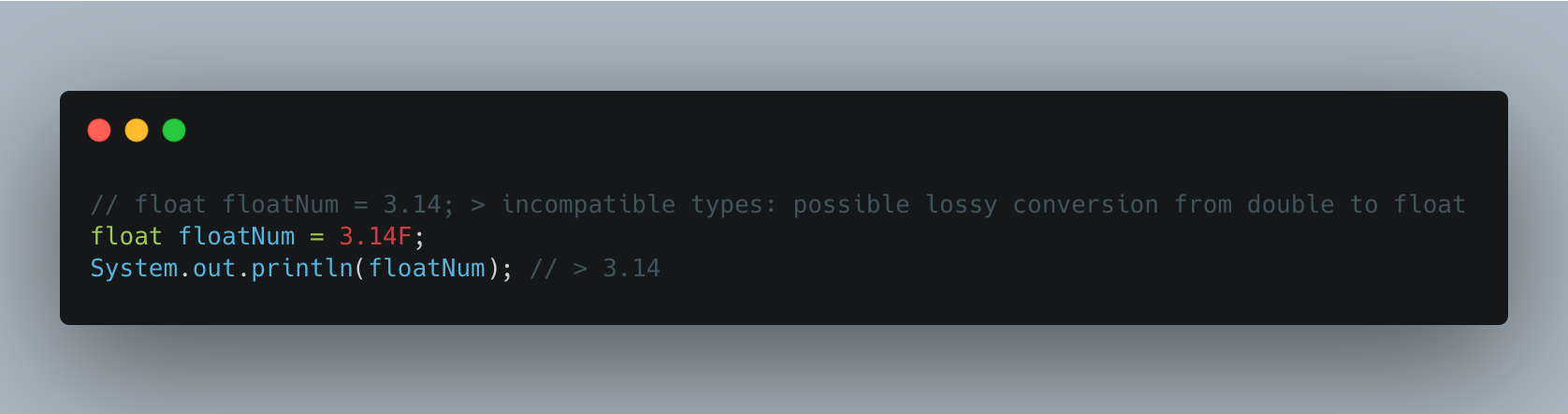
앞서 실수 자료형의 기본 자료형은 double 이기 때문에 실수를 표현할 때는 리터럴에 접미사로 f 또는 F 를 붙여줘야 한다. double 자료형의 경우 실수형의 기본 자료형이기는 하지만 float 과 마찬가지로 구별을 위해서는 d 또는 D 를 접미사로 붙여줘야 하며 정수형 중에서는 long 자료형을 사용할 때 접미사로 l 또는 L 을 사용해야 한다. 그렇지 않으면 정수형의 기본 자료형은 int 이기 때문에 오류가 발생한다.
아래 이미지를 통해 간단하게 이를 알 수 있다. float 자료형에 리터럴 접미사를 사용하지 않아서 incompatible types 라는 오류가 발생한 것을 확인할 수 있다. 아래 리터럴 접미사 F 를 사용한 경우 정상적으로 오류 없이 3.14 라는 결괏값을 출력한 걸 알 수 있다.
JDK1.7부터는 정수형 리터럴 중간에 구분자 _ 를 넣을 수 있게 되어서 큰 숫자를 편하게 읽을 수 있게 됐다. 예를 들어 기존 100000 으로 작성해야 했던 값은 이제 100_000 와 같은 형태로 쓸 수 있는 것이다.
상수 풀 (Constant Pool)¶
이전 JVM에서 메모리 영역에 대해 이야기하며 프로그램을 실행할 때 기본적으로 운영체제가 메모리에 프로그램을 할당하는 공간 중 데이터 영역(Data Area)에 관해 이야기한 적이 있다. 전역 변수와 정적 변수가 저장되는 공간 이라고도 언급했었는데 상수와 리터럴 이 바로 이 영역에 저장된다. 프로그램이 실행될 때 메모리가 로드(Load)되며 프로그램의 실행이 끝나고 언메모리 될 때 해제 된다. 데이터 영역 또는 상수 풀이라고 부른다.
타입 변환¶
변수 또는 상수의 타입을 다른 타입으로 변환하는 것을 의미한다. 이때 기본형의 경우 boolean 자료형을 제외한 나머지 자료형끼리 서로 형변환이 가능 하다. 그리고 기본형과 참조형 간의 형변환은 불가능 하다.
자동 형변환 (Type Promotion)¶
묵시적 형변환이라고도 한다. 바이트 크기가 작은 자료형에서 더 큰 자료형으로 의 형변환으로 자동으로 형변환이 이루어진다.
강제 형변환 (Type Casting)¶
명시적 형변환이라고도 한다. 바이트 크기가 더 큰 자료형을 작은 자료형으로 형변환하려는 시도인데 강제로 형변환을 수행하기 때문에 프로그래머가 이에 대한 손실이 발생 해도 그것을 감수해야한다.
기타¶
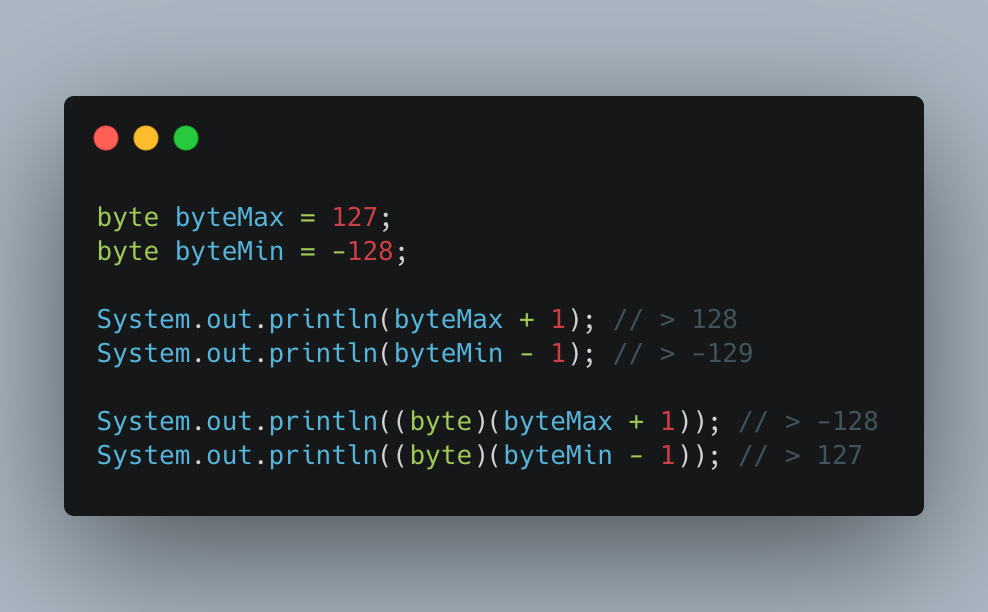
우리는 앞서 JVM의 피연산자 스택이 피연산자를 4 바이트 단위로 저장 하기 때문에 이보다 작은 자료형인 byte 와 short 의 값을 계산할 때 해당 자료형들을 4 바이트로 변환한다고 배웠다. 앞서 byte 자료형의 오버플로우 예시로 살펴 본 코드를 통해 형변환의 두 종류에 대해 다시 알아보자.
byteMax + 1 또는 byteMin - 1 연산을 수행할 경우 4 바이트 단위로 저장 돼 byteMax 와 byteMin 값이 4 바이트라서 오버플로우가 발생하지 않고 각각 128 과 -129 라는 결괏값이 출력된다. 이렇게 작은 크기의 자료형이 자연스럽게 큰 자료형으로 형변환이 발생하는 걸 자동 형변환, 타입 프로모션이라 하며 반대로 오버플로우 상황을 연출하기 위해 int 자료형 결괏값 128 과 -129 를 (byte) 와 같은 형태로 형변환 한 것을 강제 형변환, 타입 캐스팅이라 한다.
타입 추론 (Type Inference)¶
기존 스크립트 언어에서 가능했던 타입 추론이 컴파일러 언어인 자바 버전 10 이상부터 자바에서도 가능 해졌다. var 라는 키워드를 사용하여 초기화 된 값의 타입을 추론하여 변수의 자료형을 결정 할 수 있는 기능이다. 이때 유의할 점은 초기화를 하지 않으면, 다시 말해 변수에 값을 할당하지 않으면 오류가 발생한다.
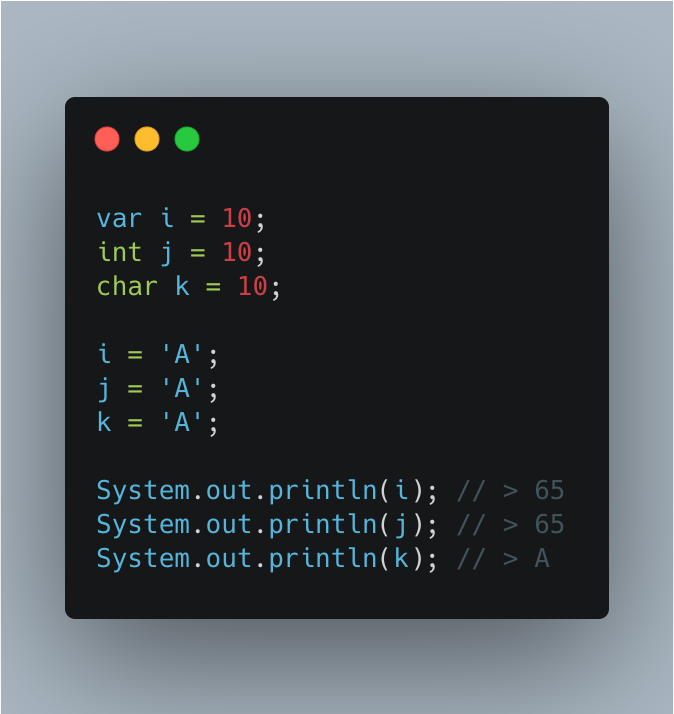
앞서 println() 은 문자형 char 자료형을 값으로 받을 경우 정수가 입력 됐을 때 유니코드에 의해 해당하는 문자를 반환한다는 것을 알 수 있었다. 아래 이미지를 통해 변수 i 에 초기화 된 값이 정수형 10 이기 때문에 i 의 자료형이 int 가 됐다. 따라서 A 라는 값을 다시 입력하더라도 char 자료형 변수 k 처럼 A 가 출력되는 것이 아니라 int 자료형 j 처럼 65 가 출력된다.
작성자: 이태현
작성일: 2021-07-11